
GitHub Repo | Technical Report
👋 Join us on Discord and WeChat
- [2025.06.06] MiniCPM4 series are released! This model achieves ultimate efficiency improvements while maintaining optimal performance at the same scale! It can achieve over 5x generation acceleration on typical end-side chips! You can find technical report here.🔥🔥🔥
MiniCPM4 series are highly efficient large language models (LLMs) designed explicitly for end-side devices, which achieves this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems.
- MiniCPM4-8B: The flagship of MiniCPM4, with 8B parameters, trained on 8T tokens.
- MiniCPM4-0.5B: The small version of MiniCPM4, with 0.5B parameters, trained on 1T tokens.
- MiniCPM4-8B-Eagle-FRSpec: Eagle head for FRSpec, accelerating speculative inference for MiniCPM4-8B.
- MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu: Eagle head trained with QAT for FRSpec, efficiently integrate speculation and quantization to achieve ultra acceleration for MiniCPM4-8B.
- MiniCPM4-8B-Eagle-vLLM: Eagle head in vLLM format, accelerating speculative inference for MiniCPM4-8B.
- MiniCPM4-8B-marlin-Eagle-vLLM: Quantized Eagle head for vLLM format, accelerating speculative inference for MiniCPM4-8B.
- BitCPM4-0.5B: Extreme ternary quantization applied to MiniCPM4-0.5B compresses model parameters into ternary values, achieving a 90% reduction in bit width. (<-- you are here)
- BitCPM4-1B: Extreme ternary quantization applied to MiniCPM3-1B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- MiniCPM4-Survey: Based on MiniCPM4-8B, accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers.
- MiniCPM4-MCP: Based on MiniCPM4-8B, accepts users' queries and available MCP tools as input and autonomously calls relevant MCP tools to satisfy users' requirements.
BitCPM4 are ternary quantized models derived from the MiniCPM series models through quantization-aware training (QAT), achieving significant improvements in both training efficiency and model parameter efficiency.
- Improvements of the training method
- Searching hyperparameters with a wind-tunnel on a small model.
- Using a two-stage training method: training in high-precision first and then QAT, making the best of the trained high-precision models and significantly reducing the computational resources required for the QAT phase.
- High parameter efficiency
- Achieving comparable performance to full-precision models of similar parameter models with a bit width of only 1.58 bits, demonstrating high parameter efficiency.
BitCPM4's parameters are stored in a fake-quantized format, which supports direct inference within the Huggingface framework.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
path = "openbmb/BitCPM4-0.5B"
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True)
messages = [
{"role": "user", "content": "推荐5个北京的景点。"},
]
model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True).to(device)
model_outputs = model.generate(
model_inputs,
max_new_tokens=1024,
top_p=0.7,
temperature=0.7
)
output_token_ids = [
model_outputs[i][len(model_inputs[i]):] for i in range(len(model_inputs))
]
responses = tokenizer.batch_decode(output_token_ids, skip_special_tokens=True)[0]
print(responses)
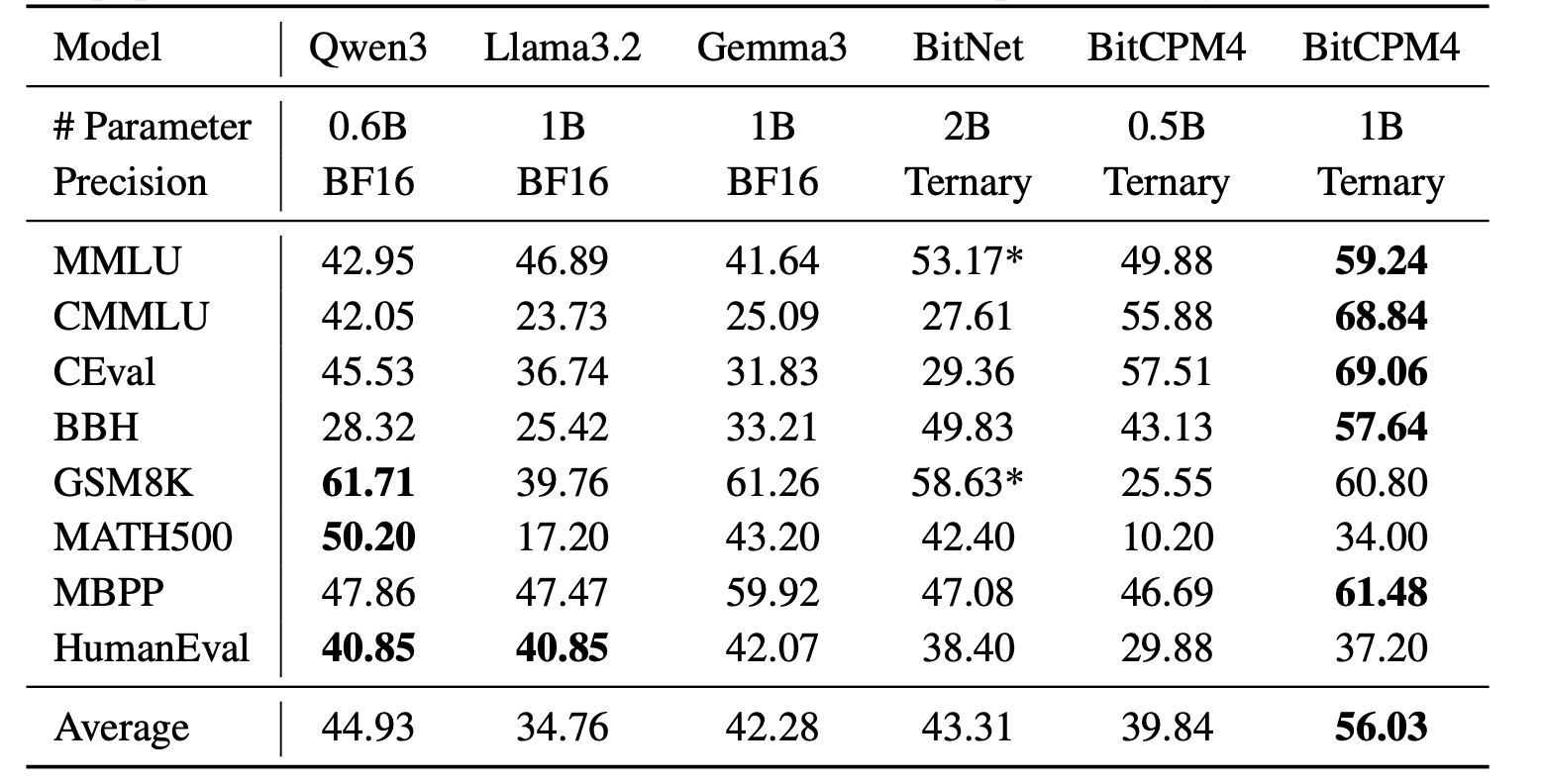
BitCPM4's performance is comparable with other full-precision models in same model size.
- As a language model, MiniCPM generates content by learning from a vast amount of text.
- However, it does not possess the ability to comprehend or express personal opinions or value judgments.
- Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
- Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
- This repository and MiniCPM models are released under the Apache-2.0 License.
- Please cite our paper if you find our work valuable.
@article{minicpm4, title={{MiniCPM4}: Ultra-Efficient LLMs on End Devices}, author={MiniCPM Team}, year={2025} }